

안녕하세요? 종 분포 모델링(SDM: Species Distribution Modeling)은 컴퓨터 알고리즘을 사용하여 지리적 시공간에 걸쳐 종의 분포를 예측하는 방법입니다. SDM은 알고리즘에 따라 출현(presence) 데이터 외에 비출현(absence) 데이터가 필요할 수 있는데요, 이번 글에서는 실제 비출현(true absence) 데이터가 없을 때, 임의 비출현 데이터(pseudo-absence)를 생성하는 방법을 정리해 보겠습니다.
호주 BCCVL(Biodiversity and Climate Change Virtual Laboratory(생물다양성 및 기후변화 가상 실험실)에서 비출현 데이터에 관해 간략히 설명한 글이 있어 링크를 공유해 봅니다. 출현과 비출현 데이터 간 개수 비율(prevalence)은 모델 정확도에 영향을 미치며 이를 고려했을 때 출현:비출현 개수 비율은 1:1이 권장되고 있습니다.
Absence Data
Depending on the species distribution modelling algorithm that you want to use, you might need absence data in addition to presence data. This can either be true absence data or pseudo-absence data. True absence data When it is repeatedly obser...
support.bccvl.org.au
BCCVL은 세가지 유형의 임의 비출현 데이터 생성 방법을 제시하고 있는데요, 가장 대표적이자 첫번째 방법은 출현 지점을 제외한 영역에서 비출현 지점을 무작위 추출하는 것입니다. 두번째 방법은 출현 지점의 환경적 조건과 대조되는 영역 내에서만 비출현 지점을 추출하는 것이고, 세번째 방법은 출현 데이터에서 최소, 최대 반경을 설정해 비출현 데이터 추출 영역을 제한하는 것입니다.

이번 글에서는 출현 데이터로부터 일정한 범위를 제외하고, 나머지 영역에서 비출현 데이터를 무작위 추출해 보겠습니다. 자, 그럼 시작해볼까요?! 일단 실습을 위한 출현 데이터는 동박새(학명: Zosterops japonicus, 영명: warbling white-eye)로 진행해 보겠습니다.

일단 필요한 모듈을 호출하고 파이썬에서 자주 접하는 경고 메시지를 비활성화 하겠습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import geopandas as gpd
import shapely.geometryimport warnings
warnings.simplefilter(action='ignore', category=FutureWarning)행정구역과 출현지점을 GeoDataFrame 객체로 정의하고 열어보겠습니다.
adm_kor = gpd.GeoDataFrame.from_file('DATA/ADM_KOR.gpkg') # 행정구역
presence = gpd.GeoDataFrame.from_file('DATA/Zosterops_japonicus.gpkg') # 출현지점 (Point)
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
adm_kor.plot(ax=ax, color='lightgray', edgecolor='white');
presence.plot(ax=ax, marker='o', color='red', markersize=5);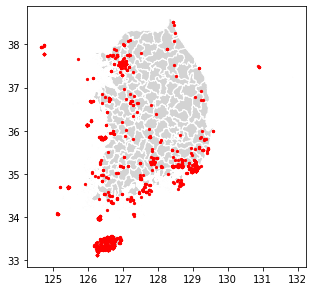
출현 데이터의 개수는 1,902개로 확인됩니다. 참고로 동박새 출현 데이터는 QGIS의 GBIFOccurrences 플러그인(https://foss4g.tistory.com/1552)을 통해 내려받았습니다.
presence.shape[0]출현 지점에서 일정 거리만큼 버퍼를 적용해 보겠습니다. 이때 버퍼거리를 미터로 적용하기 위해 좌표계를 변경 후 버퍼거리를 적용했습니다. 결과는 아래와 같습니다. 버퍼를 위한 반경은 10km로 설정했는데요, 이것은 특별히 동박새의 생태를 고려한 거리가 아니고 실습용 목적으로 임의 부여한 값입니다.
# 출현지점 버퍼
presence_bfr = presence.to_crs(5179) # 투영좌표계
presence_bfr['geometry'] = presence_bfr.geometry.buffer(10000) # 10km 버퍼
presence_bfr = presence_bfr.to_crs(4326) # 투영좌표계
presence_bfr.plot(color='red', figsize=(5, 5));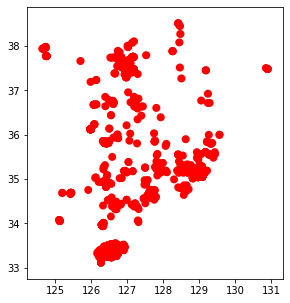
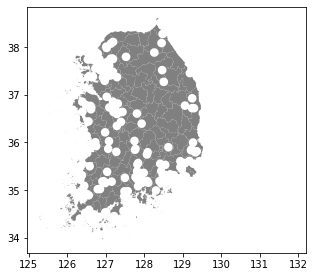
우리나라 영역에서 출현 데이터의 버퍼 영역을 제외하려면, 중첩분석을 적용하면 됩니다. 관련 사항은 GeoPandas 공식 튜토리얼(https://geopandas.org/en/stable/docs/user_guide/set_operations.html)을 확인해 보시면 좋겠습니다. 저는 여기서 'Difference'를 적용해 봤습니다. 결과는 아래와 같이 전체 영역에서 버퍼 지역이 제외된 나머지 도형으로 표현됩니다.
res_difference = adm_kor.overlay(presence_bfr, how='difference')
res_difference.plot(color='grey', figsize=(5, 5));
다음으로 무작위 표본을 생성하는 함수를 사용합니다. 관련 내용은 이전 글(https://foss4g.tistory.com/1825)을 참고해 보시면 좋겠습니다.
def random_points_in_gdf(gdf, size, overestimate=2):
polygon = gdf['geometry'].unary_union
min_x, min_y, max_x, max_y = polygon.bounds
ratio = polygon.area / polygon.envelope.area
samples = np.random.uniform((min_x, min_y), (max_x, max_y), (int(size / ratio * overestimate), 2))
multipoint = shapely.geometry.MultiPoint(samples)
multipoint = multipoint.intersection(polygon)
samples = np.array(multipoint)
points = samples[np.random.choice(len(samples), size)]
df = pd.DataFrame(points, columns=['lon', 'lat'])
return gpd.GeoDataFrame(df, geometry=gpd.points_from_xy(df.lon, df.lat))비출현 데이터는 출현 데이터 개수만큼 생성하도록 설정해 봤습니다. 결과는 다음과 같습니다.
absence = random_points_in_gdf(res_difference, presence.shape[0])
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
res_difference.plot(ax=ax, color='lightgray', edgecolor='white');
presence.plot(ax=ax, marker='o', color='red', markersize=5);
absence.plot(ax=ax, marker='o', color='blue', markersize=5);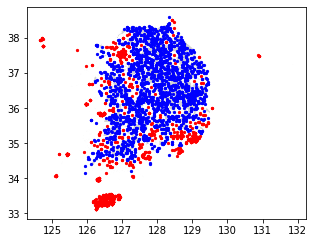
이제 출현, 비출현 데이터를 하나로 결합한 후 *.gpkg 포맷으로 파일을 저장해 주시면 되겠습니다.
gdf = presence.append(absence, ignore_index=True)
# 출현/비출현 지점 저장
gdf.crs= "+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs"
gdf.to_file('DATA/Occurrences_Zj.gpkg', driver='GPKG', name='Occurrences_Zj')지금까지 소개드린 내용을 하나의 함수로 정의해 봤습니다.
def create_absence_points(presence, total_area, radius, count=presence.shape[0]):
presence_bfr = presence.to_crs(5179)
presence_bfr['geometry'] = presence_bfr.geometry.buffer(radius)
presence_bfr = presence_bfr.to_crs(4326)
res_difference = total_area.overlay(presence_bfr, how='difference')
absence = random_points_in_gdf(res_difference, count)
absence['CLASS'] = 0
return absenceadm_kor = gpd.GeoDataFrame.from_file('DATA/ADM_KOR.gpkg') # 행정구역
presence = gpd.GeoDataFrame.from_file('DATA/Zosterops_japonicus.gpkg') # 출현지점 (Point)
absence = create_absence_points(presence, adm_kor, 10000)
absence.head()해당 소스코드는 아래 링크에서 확인하실 수 있습니다.
GitHub - osgeokr/sdm-tools
Contribute to osgeokr/sdm-tools development by creating an account on GitHub.
github.com