
안녕하세요? 이번 글은 Python 라이브러리인 libpysal과 esda를 활용하여 QGIS 내에서 공간연관성 국지지표(LISA, Local Indicators of Spatial Association)를 구현하는 Hotspot Analysis v3 플러그인을 간략히 소개하겠습니다.
플러그인에서 제공하는 분석 기능
- Getis-Ord Gi*: 통계적으로 유의한 핫스팟(고–고 군집)과 콜드스팟(저–저 군집)을 탐지
- Local Moran’s I (단변량): 국지적 공간 자기상관 및 군집/이상치 패턴(HH, LL, HL, LH) 식별
- Local Moran’s I (이변량): 두 개의 공간 속성 간 국지적 연관성 분석

출력 레이어에 포함되는 정보
- Z-score
- p-value
- q-value (Moran’s I 분석에 한해 제공)
- 기존 속성 정보 모두 유지
QGIS 플러그인 저장소에서 설치하기 (권장 방법)
QGIS 내에서 다음 절차에 따라 설치할 수 있습니다.
- 메뉴 열기: Plugins → Manage and Install Plugins 선택
- 플러그인 검색: 검색 창에 Hotspot Analysis v3 입력
- 설치 실행: Install Plugin 클릭
이 방법을 통해 QGIS 공식 저장소에 등록된 최신 승인 버전을 항상 안전하게 설치할 수 있습니다.

Hotspot Analysis v3.0.2를 사용하기 위해서는 다음 Python 라이브러리가 필요합니다.
- libpysal
- esda
해당 라이브러리가 설치되어 있지 않을 경우, 플러그인은 정상적으로 실행되지 않으며, 종속성(dependency) 관련 경고 메시지가 표시됩니다.


OSGeo4W Shell을 실행한 후, 다음 명령어를 입력하여 관련 라이브러리를 설치합니다.
python -m pip install --user libpysal esda유효한 입력 레이어 생성
이 플러그인은 좌표계가 적용된(point 또는 polygon) 쉐이프파일 중, 각 도형(객체)에 최소 하나 이상의 수치형 속성값이 할당된 데이터를 입력값으로 사용합니다. 단, 현재 버전에서는 GeoPackage(.gpkg) 형식의 파일은 정상적으로 인식하지 못하므로, 분석 전 반드시 Shapefile 형식으로 변환해야 합니다.

포인트 쉐이프파일(Point Shapefile)

핫스팟 분석을 올바르게 실행하려면, 데이터셋에는 최소 약 30개 이상의 점이 포함되어 있어야 합니다(권장 기준).
또한, 입력 쉐이프파일에 적용된 좌표계도 중요한 요구사항입니다. 이 플러그인은 투영 좌표계가 적용된 레이어만 사용할 수 있으므로, 레이어 속성에서 반드시 이를 확인해야 합니다. 아울러, 선택한 투영 좌표계가 어떤 측정 단위로 표현되어 있는지도 반드시 확인해야 합니다. 이 측정 단위는 플러그인 매개변수(예: 거리 대역, Distance Band)를 설정하는 데 매우 중요한 기준이 됩니다.
이 플러그인은 Getis-Ord Gi* 국지 통계 기법을 구현하고 있으며, 이는 특정 변수의 공간적 분포에서 비정상적인 위치(즉, 핫스팟/콜드스팟)를 탐지하는 것을 목표로 합니다. 구체적으로, Gi* 통계량은 지역 평균값을 전체 평균값과 비교하여 통계적으로 유의미한 고값(또는 저값) 군집의 존재 여부를 분석합니다.
지역 평균은 각 위치를 기준으로, 일정 거리 이내에 포함된 이웃 요소들을 고려하여 계산됩니다. 따라서, 플러그인을 사용할 때에는 입력 쉐이프파일의 투영 좌표계와 동일한 단위를 기준으로 거리 대역(Distance Band)을 지정해야 합니다.
사용자 인터페이스를 열면, 목록에서 입력 레이어를 선택한 후, 핫스팟 분석에 사용할 양의 수치형 속성값이 포함된 필드를 지정해야 합니다.



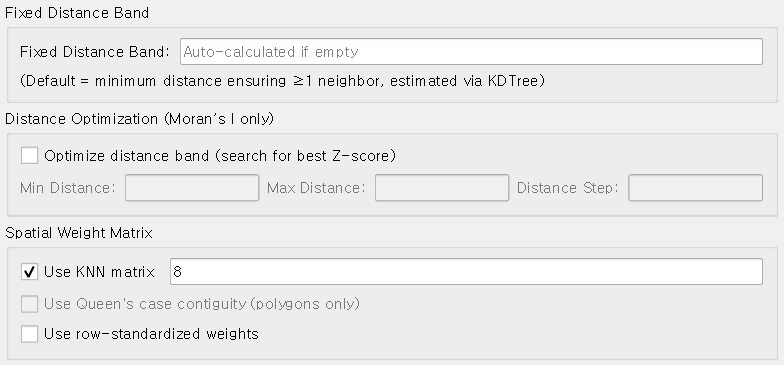
분석을 위한 적절한 거리 대역(Distance Band) 선택
앞서 설명한 바와 같이, Getis-Ord Gi* 국지 통계를 계산하기 위해서는 데이터셋 내 점들 간의 공간적 관계를 정의해야 합니다. 이 플러그인은 고정 거리 대역(Fixed Distance Band)을 사용하여 이러한 공간적 관계를 모델링합니다. 이 과정에서 PySAL의 W 객체(즉, 인접 행렬 또는 공간 가중치 행렬)가 생성됩니다.
거리 대역 설정은 분석에서 매우 중요한 단계이지만, 이를 위한 명확한 고정 규칙은 존재하지 않습니다. 분석에 사용되는 거리는 데이터가 나타내는 현상과 분석 목적에 따라 직접적으로 달라집니다.
예를 들어, 도시 내 블록별 범죄 발생 핫스팟을 분석하는 경우, 분석 거리는 인접한 도시 블록 간 평균 거리 수준이 될 수 있습니다. 다만, 일반적으로 각 지점에 대해 일정 수 이상의 이웃이 확보되도록 거리를 설정하는 것이 바람직합니다.
신뢰도 높은 분석 결과를 얻기 위해서는, “고립점(island)” 발생을 방지하고자 다음 기준을 권장합니다.
- 소규모 데이터셋: 약 8개 이상 이웃 확보
- 대규모 데이터셋: 약 30개 이상 이웃 확보
기본적으로 제안되는 고정 거리 대역 값은, 모든 점이 최소 1개 이상의 이웃을 가질 수 있도록 보장하는 최소 거리입니다. 이 값은 오직 점들의 공간적 분포만을 고려하여 산정됩니다. 사용자는 필요에 따라 이 값을 변경할 수 있으나, 기본 제안 값보다 더 작은 거리를 설정하는 것은 피해야 합니다.

이 플러그인에는 거리 대역(Distance Band)을 자동으로 최적화하는 기능이 포함되어 있습니다. 이 기능을 사용하려면 Optimize Distance Band 옵션을 체크하여 활성화하면 되며, 해당 옵션을 선택하면 Fixed Distance Band 항목은 자동으로 비활성화됩니다.

이후 최소 거리(Min Distance), 최대 거리(Max Distance), 그리고 거리 간격(Distance Step)을 직접 입력하여 거리 범위를 설정해야 합니다.
예를 들어,
- Min Distance = 10,000 m
- Max Distance = 30,000 m
- Distance Step = 1,000 m
로 설정할 경우, 알고리즘은 다음과 같은 거리 배열을 순차적으로 테스트합니다.
[10,000 m, 11,000 m, …, 29,000 m, 30,000 m]
이 중에서 핫스팟 분석에 자동으로 적용될 최적 거리값은, 데이터셋의 전역 Moran’s I 지수의 Z-score를 최대화하는 값으로 선정됩니다. 이 지수는 데이터셋이 어느 분석 거리에서 고값 또는 저값 군집 활동이 가장 활발하게 나타나는지를 보여주며, 단순한 점의 공간 분포뿐만 아니라, 분석에 사용된 수치형 속성값의 공간적 배열까지 함께 고려합니다.
다만, 자동으로 제안된 거리값이 항상 분석 목적과 일치하지 않을 수도 있으므로 주의가 필요합니다. 따라서 분석 목적에 적합한 거리 범위를 직접 설정하는 것이 바람직하며, 최소 거리는 반드시 각 지점이 최소 1개 이상의 이웃을 가질 수 있는 거리 이상으로 지정해야 합니다. 이는 공간 가중치 행렬에서 고립점(island) 발생을 방지하기 위함입니다.
또한, 최적화 과정에 소요되는 계산 시간은 데이터 포인트 수에 따라 증가할 뿐만 아니라, 설정한 거리 범위와 간격에도 크게 영향을 받습니다. 즉, 거리 범위가 넓고, 간격이 작을수록 계산 시간이 길어집니다. 따라서 분석 목적과 시스템 환경을 고려하여 적절한 범위와 간격을 설정하는 것이 중요합니다.
포인트 자료의 공간 가중치는 고정 거리 대역(Fixed Distance Band)과 최근접 이웃 방식(KNN) 중 하나를 선택하여 적용하실 수 있습니다. KNN을 선택하실 경우, 고정 거리 대역은 자동으로 비활성화됩니다.
폴리곤 쉐이프파일(Polygon Shapefile)

입력 레이어가 폴리곤 쉐이프파일인 경우, 플러그인은 이를 자동으로 인식하고 Fixed Distance Band 옵션을 비활성화합니다. 이는 폴리곤 간의 공간적 관계가 1차 Queen 인접성 공간 가중치 행렬(first order queen’s case spatial weights matrix)을 사용하여 모델링되기 때문입니다. 따라서 두 폴리곤은 최소 한 개의 꼭짓점을 공유할 경우 이웃으로 정의됩니다.

이 경우에도 유효한 입력 레이어는 데이터셋의 각 지오메트리에 대해 최소 하나 이상의 수치형 속성을 포함하고 있어야 합니다. 또한, 공간 가중치 행렬에서 “고립점(island)”과 같은 단절 영역이 발생하지 않도록, 데이터셋의 지오메트리는 빈 공간이나 구멍이 없는 연속적인 영역을 대표해야 합니다.
플러그인 옵션 및 실행(Plugin options and run)
입력 레이어, 속성, 공간적 관계가 정의되면, 출력 파일의 이름과 경로를 지정한 뒤 확인(OK) 버튼을 눌러 핫스팟 분석을 실행할 수 있습니다. 사용자의 목적에 맞게 Gi* 검정을 조정할 수 있는 여러 옵션이 제공됩니다.
“Use row standardized spatial weights(행 표준화 공간 가중치 사용)” 옵션을 활성화하면, 공간 가중치 행렬이 수정됩니다. 기본 가중치는 이진(binary) 형태로, 이웃이면 1, 아니면 0으로 설정됩니다. 행 표준화 가중치를 사용하면, 각 행의 모든 요소를 해당 행의 합으로 나누게 됩니다. 이를 통해 이웃이 많은 지역과 이웃이 적은 지역 간의 영향력이 균형 있게 조정됩니다.


또 다른 옵션으로는, 귀무가설이 참일 때(귀무가설 = 완전 공간 무작위성, CSR) 검정 통계량의 표본분포를 계산하기 위해 순열(permutation) 방식을 사용하는 기능이 있습니다. 이 기능은 “Use random permutations(무작위 순열 사용)” 체크박스를 통해 활성화할 수 있습니다. 기본 순열 횟수는 999회이며, 전용 입력창에 숫자를 입력하여 변경할 수 있습니다. 무작위 순열 방식을 사용하지 않을 경우, 검정 통계량의 표본분포는 기본적으로 표준정규분포(Standard Normal Distribution)를 따른다고 가정하여 근사 계산됩니다.

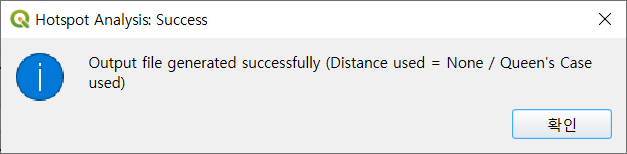
분석 과정이 완료되면, 성공 메시지가 표시되며 결과 레이어가 자동으로 QGIS 지도 패널에 추가됩니다. 이 성공 메시지에는 사용자가 설정한 거리 대역(Distance Band) 정보도 함께 포함됩니다. 폴리곤 레이어를 대상으로 분석한 경우에는, 성공 메시지에 해당 방식이 사용되었음을 별도로 안내합니다. 앞서 설명한 것처럼, 출력 결과 생성에는 설정한 매개변수에 따라 일정 시간이 소요될 수 있습니다.

생성된 결과 레이어에는 자동 스타일이 적용되며, 이를 통해 핫스팟과 콜드스팟을 통계적 유의성과 함께 시각적으로 구분할 수 있습니다.
결과 해석
출력 레이어는 입력 레이어를 복사한 형태이며, 속성 테이블에는 두 개의 새로운 필드가 추가되어 있습니다. 이 필드에는 데이터셋의 각 객체에 대한 Gi*의 Z-score와 이에 대응하는 p-value가 저장됩니다.
출력 레이어의 기본 스타일은 Z-score와 p-value의 조합을 활용하여 핫스팟과 콜드스팟을 구분하고, 동시에 통계적 유의성을 시각적으로 표현합니다. 임계값(threshold value)은 정규표준분포를 기준으로 설정됩니다. 출력 스타일은 사용자의 분석 목적과 필요에 따라 자유롭게 변경할 수 있습니다.

핫스팟은 주변 역시 높은 값을 가진 지점들로 둘러싸인, 비정상적으로 높은 값이 집중된 위치를 의미합니다(콜드스팟은 그 반대입니다). 통계적으로 유의하지 않은 지점은 국지적 값이 무작위적으로 분포되어 있어, 의미 있는 군집이 형성되지 않은 위치를 나타냅니다.
이 분석 과정은 데이터셋에 내재된 숨겨진 공간적 패턴을 파악하는 데 중요한 역할을 하며, 비정상적인 위치를 강조함으로써 공간 분포 특성을 효과적으로 설명하고 시각화할 수 있도록 해줍니다.
[출처]
- Oxoli, D., Prestifilippo, G., Bertocchi, D., Zurbaràn, M. (2017). Enabling spatial autocorrelation mapping in QGIS: The Hotspot Analysis Plugin. GEAM. GEOINGEGNERIA AMBIENTALE E MINERARIA, 151(2), 45-50.
- https://github.com/geografiadascoisas/HotSpotAnalysis_Plugin
- https://en.wikipedia.org/wiki/Spatial_weight_matrix
- https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/what-is-a-z-score-what-is-a-p-value.htm