
안녕하세요? 이번 글은 시리즈 글의 일부로 Google Earth Engine과 geemap을 이용한 종 분포 모델링(SDM: Species Distribution Modeling) 구현 방법을 소개해 보겠습니다. 이 글의 내용은 스미소니언 보전생물연구소 연구진 분들이 제공한 JavaScript 소스코드를 Python으로 변환하여 수정, 보완한 것입니다.
Crego, R. D., Stabach, J. A., & Connette, G. (2022). Implementation of species distribution models in Google Earth Engine. Diversity and Distributions, 28, 904–916. https://doi.org/10.1111/ddi.13491
사례 연구 1: 출현-전용 데이터를 이용한 팔색조(Pitta nympha) 서식지 적합성 및 예측 분포 모델링
4. 임의-비출현 데이터 생성
모델을 적합(학습)하는데 출현 데이터와 함께 임의-비출현(pseudo-absence) 데이터를 생성합니다. 이에 앞서 임의-비출현 데이터가 생성될 영역(AreaForPA)을 정의해야 합니다.
여기서는 세가지 방법을 제시합니다: 1) 전체 관심 영역에서 무작위 임의-비출현 데이터 생성, 2) 공간 제약된 임의-비출현 데이터 생성(출현 데이터 버퍼), 3) 환경적 임의-비출현 데이터 생성(Enviromental profiling). 모든 방법은 출현 위치 픽셀과 수역 픽셀을 제외(마스킹)하고 관심 영역(AOI) 내에서 처리됩니다.
4.1. 전체 관심 영역에서 무작위 임의-비출현 데이터 생성
# AreaForPA
presence_mask = Data.reduceToImage(
properties=['random'],
reducer=ee.Reducer.first()
).reproject('EPSG:4326', None, ee.Number(GrainSize)).mask().neq(1).selfMask()
AreaForPA = presence_mask.updateMask(watermask).clip(AOI)
Map = geemap.Map()
Map.addLayer(AreaForPA, {'palette': 'black'},'AreaForPA')
Map.centerObject(Data.geometry(), 7)
Map
4.2. 공간 제약된 임의-비출현 데이터 생성(출현 데이터 버퍼)
presence_mask = Data.reduceToImage(
properties=['random'],
reducer=ee.Reducer.first()
).reproject('EPSG:4326', None, ee.Number(GrainSize)).mask().neq(1).selfMask()
presence_buffer_mask = Data.geometry().buffer(distance=50000, maxError=1000)
AreaForPA = presence_mask.clip(presence_buffer_mask).updateMask(watermask).clip(AOI)
Map = geemap.Map()
Map.addLayer(AreaForPA, {'palette': 'black'},'AreaForPA')
Map.centerObject(Data.geometry(), 7)
Map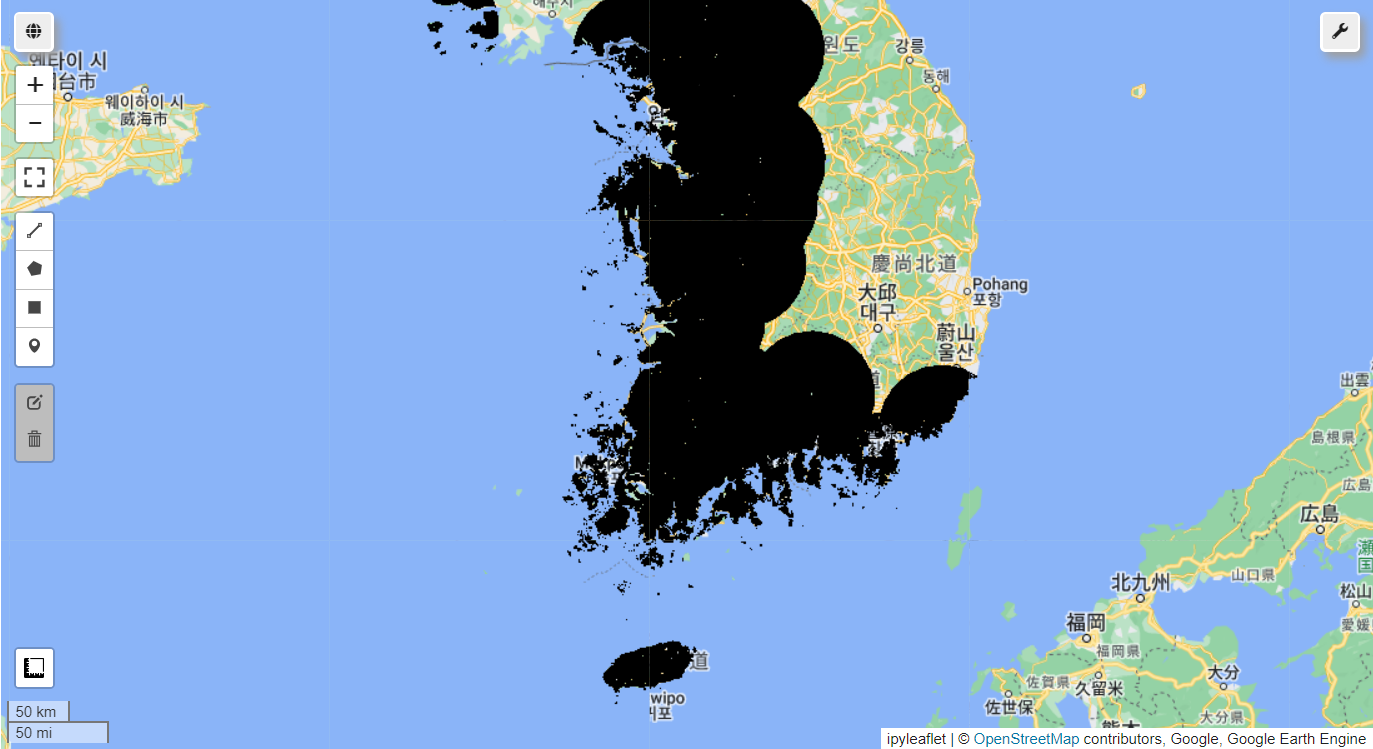
4.3. 환경적 임의-비출현 데이터 생성(Enviromental profiling)
환경 프로파일링 접근법(environmental profiling approach)은 유클리드 거리(Euclidean distance)를 기반으로 k-평균 클러스터링을 통해 2개 클러스터를 생성한 후, 출현 데이터와 덜 유사하게 분류된 클러스터 내에서 임의-비출현 데이터를 생성하는 방식입니다.
presence_mask = Data.reduceToImage(
properties=['random'],
reducer=ee.Reducer.first()
).reproject('EPSG:4326', None, ee.Number(GrainSize)).mask().neq(1).selfMask()
# 출현 데이터의 임의 부분집합에서 예측 변수 값 추출
PixelVals = predictors.sampleRegions(
collection=Data.randomColumn().sort('random').limit(100),
properties=[],
tileScale=16,
scale=GrainSize
)
# k-평균 클러스터링 훈련
clusterer = ee.Clusterer.wekaKMeans(
nClusters=2,
distanceFunction="Euclidean"
).train(PixelVals)
# 훈련된 클러스터러를 사용하여 픽셀 할당
Clresult = predictors.cluster(clusterer)
# 출현 데이터와 유사한 클러스터 ID 획득
clustID = Clresult.sampleRegions(
collection=Data.randomColumn().sort('random').limit(200),
properties=[],
tileScale=16,
scale=GrainSize
)
# 반대 클러스터 사용, 임의-비출현 허용 영역 정의
clustID = ee.FeatureCollection(clustID).reduceColumns(ee.Reducer.mode(),['cluster'])
clustID = ee.Number(clustID.get('mode')).subtract(1).abs()
cl_mask = Clresult.select(['cluster']).eq(clustID)
AreaForPA = presence_mask.updateMask(cl_mask).clip(AOI)
Map = geemap.Map()
Map.addLayer(AreaForPA, {'palette': 'black'},'AreaForPA')
Map.centerObject(Data.geometry(), 7)
Map
다음으로 공간 블록 교차-검증용 격자(Grid for spatial block cross-validation)을 생성합니다.
# Grid for spatial block cross-validation 생성
def makeGrid(geometry, scale):
# 경도 & 위도 도 단위 이미지 생성
lonLat = ee.Image.pixelLonLat()
# 경도 & 위도 이미지 정수화
lonGrid = lonLat.select('longitude').multiply(100000).toInt()
latGrid = lonLat.select('latitude').multiply(100000).toInt()
return lonGrid.multiply(latGrid).reduceToVectors(
# geometry경계 포함 격자 생성
geometry = geometry.buffer(distance=20000, maxError=1000),
scale = scale,
geometryType = 'polygon'
)
Scale = 50000
grid = makeGrid(AOI, Scale)
Grid = watermask.reduceRegions(
collection=grid,
reducer=ee.Reducer.mean()).filter(ee.Filter.neq('mean', None))
Map = geemap.Map()
Map.addLayer(Grid, {}, "Grid for spatial block cross validation")
Map.addLayer(outline, {'palette': 'FF0000'}, "Study Area")
Map.centerObject(Data.geometry(), 6)
Map
